4.7 非核心功能
在日常的互联网项目开发中,一般先快速开发出一个最小可运行版本(MVP),投入市场验证。之后快速迭代,并进行其他非核心功能的开发。本文介绍聊天室的一些非核心功能如何实现。
说明:这里涉及到的功能,对一个聊天室来说,并不一定就是非核心功能。只是针对本书来说,它是非核心功能,因为没有它们,聊天室也可以正常运作。当然,核心还是非核心,并没有严格的界定。
4.7.1 @ 提醒功能
现在各种聊天工具或社区类网站,基本会支持 @ 提醒的功能。我们的聊天室如何实现它呢?
可以有两种做法:
- @ 当做私聊,这条消息只会发给被 @ 的人,这么做的比较少,不过我们可以看如何实现;
- 所有人都能收到,但被 @ 的人有不一样的显示提醒;
私信
先看第一种,只关注服务端的实现,但要告知对方这是一条私信。
在广播器中给所有用户广播消息时,做了一个过滤:消息不发给自己。
for _, user := range b.users {
if user.UID == msg.User.UID {
continue
}
user.MessageChannel <- msg
}
私信因为是发给一个人,因此没必要遍历所有人。根据我们的设计,可以直接取出目标用户,进行消息发送。
为了方便服务端和客户端知晓这是一条私信消息,同时服务端发送前知道这是发给谁,在 Message 结构中增加一个字段 To:
type Message struct {
// 哪个用户发送的消息
User *User `json:"user"`
Type int `json:"type"`
Content string `json:"content"`
MsgTime time.Time `json:"msg_time"`
// 消息发送给谁,表明这是一条私信
To string `json:"to"`
Users map[string]*User `json:"users"`
}
接着在接收用户发送消息的地方,对接收到的用户消息进行解析,为 Message.To 字段赋值。
// logic/user.go 中的 ReceiveMessage 方法
// 内容发送到聊天室
sendMsg := NewMessage(u, receiveMsg["content"])
// 解析 content,看是否是一条私信消息
sendMsg.Content = strings.TrimSpace(sendMsg.Content)
if strings.HasPrefix(sendMsg.Content, "@") {
sendMsg.To = strings.SplitN(sendMsg.Content, " ", 2)[0][1:]
}
这句代码别感到奇怪:strings.SplitN(sendMsg.Content, " ", 2)[0][1:] ,Go 中,函数/方法返回的 slice 可以直接取值、reslice。
注意:这个实现要求必须是 @ 开始,消息中间的 @ 没有进行处理。
在广播器中需要对接收到的消息进行处理,由原来的代码改为(else 部分):
if msg.To == "" {
// 给所有在线用户发送消息
for _, user := range b.users {
if user.UID == msg.User.UID {
continue
}
user.MessageChannel <- msg
}
} else {
if user, ok := b.users[msg.To]; ok {
user.MessageChannel <- msg
} else {
// 对方不在线或用户不存在,直接忽略消息
log.Println("user:", msg.To, "not exists!")
}
}
这里如果用户不存在或不在线,选择了直接忽略。当然可以有其他处理方法,比如当做普通广播消息发给所有人或提示发送者,对方目前的状态。
被 @ 的人收到提醒
这种方式是普遍采用的方式,聊天室中所有人都能收到消息,但被 @ 的人有提醒。
首先,我们依然需要在 Message 结构中增加一个 Ats 字段,表示能够一次 @ 多个人。
type Message struct {
// 哪个用户发送的消息
User *User `json:"user"`
Type int `json:"type"`
Content string `json:"content"`
MsgTime time.Time `json:"msg_time"`
// 消息 @ 了谁
Ats []string `json:"ats"`
Users map[string]*User `json:"users"`
}
其次,在 User 接收消息时(ReceiveMessage),同样需要解析出 @ 谁了。这次我们解析出所有被 @ 的人,而且不区分是不是以 @ 开始。
// logic/user.go 中的 ReceiveMessage 方法
// 内容发送到聊天室
sendMsg := NewMessage(u, receiveMsg["content"])
// 解析 content,看看 @ 谁了
reg := regexp.MustCompile(`@[^\s@]{2,20}`)
sendMsg.Ats = reg.FindAllString(sendMsg.Content, -1)
这里要求昵称必须 2-20 个字符,跟前面的昵称校验保持一致。(昵称没有做特殊字符处理)
以上就是服务端要做的事情。
下面看看前端。因为前端不是重点,我们只会简单的提示有人 @ 你,在将消息 push 到 msgList 之前做提示,5 秒后消失。
if (data.ats != null) {
data.ats.forEach(function(nickname) {
if (nickname == '@'+that.nickname) {
that.usertip = '有人 @ 你了';
}
})
}
效果图如下:

注意,以上做法,方法 1 代码在仓库中没有保留,方法 2 保留了。
4.7.2 敏感词处理
任何由用户产生内容的公开软件,都必须做好敏感词的处理。作为一个聊天室,当然要处理敏感词。
其实敏感词(包括广告)检测一直以来都是让人头疼的话题,很多大厂,比如微信、微博、头条等,每天产生大量内容,它们在处理敏感词这块,会投入很多资源。所以,这不是一个简单的问题,本书不可能深入探讨,但尽可能多涉及一些相关内容。
一般来说,目前敏感词处理有如下方法:
- 简单替换或正则替换
- DFA(Deterministic Finite Automaton,确定性有穷自动机算法)
- 基于朴素贝叶斯分类算法
1)简单替换或正则替换
// 1. strings.Replace
keywords := []string{"坏蛋", "坏人", "发票", "傻子", "傻大个", "傻人"}
content := "不要发票,你就是一个傻子,只会发呆"
for _, keyword := range keywords {
content = strings.ReplaceAll(content, keyword, "**")
}
fmt.Println(content)
// 2. strings.Replacer
replacer := strings.NewReplacer("坏蛋", "**", "坏人", "**", "发票", "**", "傻子", "**", "傻大个", "**", "傻人", "**")
fmt.Println(replacer.Replace("不要发票,你就是一个傻子,只会发呆"))
// Output: 不要**,你就是一个**,只会发呆
类似于上面的代码(两种代码类似),我们会使用一个敏感词列表(坏蛋、发票、傻子、傻大个、傻人),来对目标字符串进行检测与替换。比较适合于敏感词列表和待检测目标字符串都比较小的场景,否则性能会有较大影响。(正则替换和这个是类似的)
2)DFA
DFA 基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比方案 1 高不少。
假设我们有以下 6 个敏感词需要检测:坏蛋、发票、傻子、傻大个、傻人。那么我们可以先把敏感词中有相同前缀的词组合成一个树形结构,不同前缀的词分属不同树形分支,以上述 6 个敏感词为例,可以初始化成如下 3 棵树:
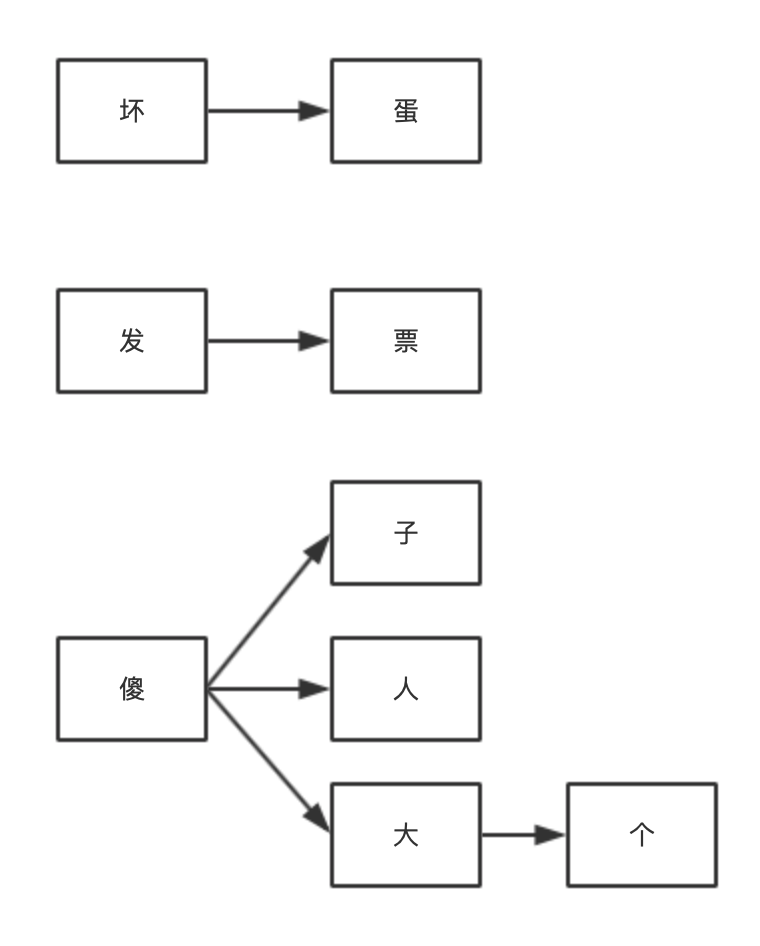
把敏感词组成树形结构有什么好处呢?最大的好处就是可以减少检索次数,我们只需要遍历一次待检测文本,然后在敏感词库中检索出有没有该字符对应的子树就行了,如果没有相应的子树,说明当前检测的字符不在敏感词库中,则直接跳过继续检测下一个字符;如果有相应的子树,则接着检查下一个字符是不是前一个字符对应的子树的子节点,这样迭代下去,就能找出待检测文本中是否包含敏感词了。
我们以文本“不要发票,你就是一个傻子,只会发呆”为例,我们依次检测每个字符,因为前 2 个字符都不在敏感词库里,找不到相应的子树,所以直接跳过。当检测到“发”字时,发现敏感词库中有相应的子树,我们把它记为 tree-1,接着再搜索下一个字符“票”是不是子树 tree-1 的子节点,发现恰好是,接下来再判断“票”这个字符是不是叶子节点,如果是,则说明匹配到了一个敏感词了,在这里“票”这个字符刚好是 tree-1 的叶子节点,所以成功检索到了敏感词:“发票”。接着检测,“你就是一个”这几个字符都没有找到相应的子树,跳过。检测到“傻”字时,处理过程和前面的“发”是一样的,“傻子”的检测过程略过。
接着往后检测,“只会”也跳过。当检测到“发”字时,发现敏感词库中有相应的子树,我们把它记为 tree-3,接着再搜索下一个字符“呆”是不是子树 tree-3 的子节点,发现不是,因此这不是一个敏感词。
大家发现了没有,在我们的搜索过程中,我们只需要扫描一次被检测文本就行了,而且对于被检测文本中不存在的敏感词,如这个例子中的“坏蛋”、“傻大个”和“傻人”,我们完全不会扫描到,因此相比方案一效率大大提升了。
Go 中有一个库实现了该算法:github.com/antlinker/go-dirtyfilter。
3)基于朴素贝叶斯分类算法
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。这是一种“半学习”形式的方法,它的准确性依赖于先验概率的准确性。
Go 中有一个库实现了该算法:github.com/jbrukh/bayesian。
小结
对于聊天室来说,每次的内容比较少,简单替换就可以满足大部分需求。实际中会涉及比较多的变种,比如敏感词中间加一些其他字符,有一个简单的方法是初始化一个无效字符库,比如:空格、*、#、@等字符,然后在检测文本前,先将待检测文本中的无效字符去除,这样的话被检测字符中就不存在这些无效字符了。
聊天室加上敏感词处理
聊天室一般发送的内容比较短,因此可以采用简单替换的方法。为了方便随时对敏感词列表进行修改,将敏感词存入配置文件中,通过 viper 库来处理配置文件。
由于不确定哪些地方可能需要用到配置文件中的内容,因此要求配置文件解析尽可能早的进行,同时方便其他地方进行引用或读取。因此进行代码重构,新创建一个包:global,用来存放配置文件和项目根目录等一些全局用的代码。
// global/init.go
func init() {
Init()
}
var RootDir string
var once = new(sync.Once)
func Init() {
once.Do(func() {
inferRootDir()
initConfig()
})
}
// inferRootDir 推断出项目根目录
func inferRootDir() {
cwd, err := os.Getwd()
if err != nil {
panic(err)
}
var infer func(d string) string
infer = func(d string) string {
// 这里要确保项目根目录下存在 template 目录
if exists(d + "/template") {
return d
}
return infer(filepath.Dir(d))
}
RootDir = infer(cwd)
}
func exists(filename string) bool {
_, err := os.Stat(filename)
return err == nil || os.IsExist(err)
}
以上代码核心要讲解的是 sync.Once。该类型的 Do 方法中的代码保证只会执行一次。这正好符合根目录推断和配置文件读取和解析。根据 Go 语言包的执行顺序,我们将相关初始化方法放在了单独的 Init 函数中,然后在 main.go 的 init 方法中调用它:
func init() {
global.Init()
}
为了支持敏感词的动态修改,及时生效,在 global 包中的 config.go 文件做相关处理:
// global/config.go
var (
SensitiveWords []string
)
func initConfig() {
viper.SetConfigName("chatroom")
viper.AddConfigPath(RootDir + "/config")
if err := viper.ReadInConfig(); err != nil {
panic(err)
}
SensitiveWords = viper.GetStringSlice("sensitive")
viper.WatchConfig()
viper.OnConfigChange(func(e fsnotify.Event) {
viper.ReadInConfig()
SensitiveWords = viper.GetStringSlice("sensitive")
})
}
其他配置项,如果不希望每次都通过 viper 调用获取,可以定义为 global 的包级变量,供其他地方使用。
配置文件放在项目根目录的 config/chatroom.yaml 中:
sensitive:
- 坏蛋
- 坏人
- 发票
- 傻子
- 傻大个
- 傻人
在接收到用户发送的消息后,对敏感词进行处理。在 logic/user.go 的 ReceiveMessage 方法中增加对以下函数的调用:sendMsg.Content = FilterSensitive(sendMsg.Content)
// logic/sensitive.go
func FilterSensitive(content string) string {
for _, word := range global.SensitiveWords {
content = strings.ReplaceAll(content, word, "**")
}
return content
}
当用户发送:不要发票,你就是一个傻子,只会发呆。最终效果:

4.7.3 离线消息处理(更确切说是最近的消息)
当用户不在线时,这期间发送的消息,是否需要存储,等下次上线时发送给 TA,这就是离线消息处理。
一般来说,聊天室不需要处理离线消息,而且我们的聊天室没有实现注册功能,同一个昵称不同时间可能被不同人使用,因此离线消息存储的意义不大。但有两种情况可以保存离线消息。
- 对某个用户的 @ 消息
- 最近发送的 10 条消息
我们聊天室要做到离线消息存储,需要解决一个问题:用户退出再登录,确保是同一个人,而不是另外一个人用了相同的昵称。但因为我们没有实现注册功能,于是这里需要对用户登录后进行一些处理。
1、正确识别同一个用户
目前聊天室虽然通过前端的 localStorage 存储了用户信息,方便记住和让同一个用户自动进入聊天室,但只要用户退出再登录,用户的 UID 就会变。为了正确识别同一个用户,我们需要保证同一个用户的 UID 和昵称都不变。
因为我们的聊天室不要求登录,为了更好的识别同一用户,同时避免恶意用户直接修改 localStorage 的数据,在用户进入聊天室时,为其生成一个 token,用来标识该用户,token 和用户昵称一起,存入 localStorage 中。
因为之前 localStorage 只是存储了用户昵称,所以需要进行修改。
- 之前的 nickname 改为 curUser,包含 nickname、uid 和 token 等用户信息;
- localStorage 中存入 curUser,通过 json 进行系列化后存入:localStorage.setItem(‘user’, JSON.stringify(data.user))
- 建立 WebSocket 连接时,除了之前的 nickname,额外传递 token:new WebSocket(“ws://“+host+”/ws?nickname="+this.curUser.nickname+”&token="+this.curUser.token);
为此,服务端要需要进行相关的修改。首先 User 结构增加两个字段:isNew bool 和 token string ,isNew 用来判断进来的用户是不是第一次加入聊天室。相应的,NewUser 方法修改为:
func NewUser(conn *websocket.Conn, token, nickname, addr string) *User {
user := &User{
NickName: nickname,
Addr: addr,
EnterAt: time.Now(),
MessageChannel: make(chan *Message, 8),
Token: token,
conn: conn,
}
if user.Token != "" {
uid, err := parseTokenAndValidate(token, nickname)
if err == nil {
user.UID = uid
}
}
if user.UID == 0 {
user.UID = int(atomic.AddUint32(&globalUID, 1))
user.Token = genToken(user.UID, user.NickName)
user.isNew = true
}
return user
}
当没有传递 token 时,当做新用户处理,为用户生成一个 token:
// logic/user.go
func genToken(uid int, nickname string) string {
secret := viper.GetString("token-secret")
message := fmt.Sprintf("%s%s%d", nickname, secret, uid)
messageMAC := macSha256([]byte(message), []byte(secret))
return fmt.Sprintf("%suid%d", base64.StdEncoding.EncodeToString(messageMAC), uid)
}
func macSha256(message, secret []byte) []byte {
mac := hmac.New(sha256.New, secret)
mac.Write(message)
return mac.Sum(nil)
}
token 的生成算法:
- 基于 HMAC-SHA256;
- nickname+secret+uid 构成待 hash 的字符串,记为:message
- 将 message 使用 HMAC-SHA256 计算 hash,记为:messageMAC
- 将 messageMAC 使用 base64 进行处理,记为:messageMACStr
- messageMACStr+“uid”+uid 就是 token
接着看看 token 的解析和校验,解析是为了得到 uid:
// logic/user.go
func parseTokenAndValidate(token, nickname string) (int, error) {
pos := strings.LastIndex(token, "uid")
messageMAC, err := base64.StdEncoding.DecodeString(token[:pos])
if err != nil {
return 0, err
}
uid := cast.ToInt(token[pos+3:])
secret := viper.GetString("token-secret")
message := fmt.Sprintf("%s%s%d", nickname, secret, uid)
ok := validateMAC([]byte(message), messageMAC, []byte(secret))
if ok {
return uid, nil
}
return 0, errors.New("token is illegal")
}
func validateMAC(message, messageMAC, secret []byte) bool {
mac := hmac.New(sha256.New, secret)
mac.Write(message)
expectedMAC := mac.Sum(nil)
return hmac.Equal(messageMAC, expectedMAC)
}
总体的思路就是按照生成 token 的方式,再得到一次 token,然后跟用户传递的 token 进行比较。因为 HMAC-SHA256 得到的结果是二进制的,因此相等比较使用了 hmac 包的 Equal 函数。这里大家可以借鉴下 uid 放入 token 中的技巧。
2、离线消息的实现
能够正确识别用户后,就可以来实现离线消息了。
在 logic 包中创建一个 offline.go 文件,创建 offlineProcessor 结构体对外提供一个单实例:OfflineProcessor。
type offlineProcessor struct {
n int
// 保存所有用户最近的 n 条消息
recentRing *ring.Ring
// 保存某个用户离线消息(一样 n 条)
userRing map[string]*ring.Ring
}
var OfflineProcessor = newOfflineProcessor()
func newOfflineProcessor() *offlineProcessor {
n := viper.GetInt("offline-num")
return &offlineProcessor{
n: n,
recentRing: ring.New(n),
userRing: make(map[string]*ring.Ring),
}
}
由于资源的限制,而且我们是直接将离线消息存在进程的内存中,因此不可能保留所有消息,而是保存最近的 n 条消息,其中 n 可以通过配置文件进行配置。这样的需求,标准库 container/ring 刚好满足。
container/ring 详解
这个包代码量很少,有效代码行数:87,包含注释和空格也就 141 行。因此,我们可以详细学习下它的实现。
从名字知晓,ring 实现了一个环形的链表,因此它没有起点或终点,指向环中任何元素的指针都可用作整个环的引用。空环表示为 nil 环指针。环的零值是一个包含一个元素,元素值是 nil 的环,如:
var r ring.Ring
fmt.Println(r.Len()) // Output: 1
fmt.Println(r.Value) // Output: nil
但实际使用时,应该通过 New 函数来获得一个 Ring 的实例指针。
看看 Ring 结构体:
type Ring struct {
next, prev *Ring
Value interface{} // for use by client; untouched by this library
}
该结构体同时包含了 next 和 prev 字段,方便进行正反两个方向进行移动。我们可以通过 ring.New(n int) 函数得到一个 Ring 的实例指针,n 表示环的元素个数。
func New(n int) *Ring {
if n <= 0 {
return nil
}
r := new(Ring)
p := r
for i := 1; i < n; i++ {
p.next = &Ring{prev: p}
p = p.next
}
p.next = r
r.prev = p
return r
}
New 函数一共创建了 n 个 Ring 实例指针,在 for 循环中,将这 n 个 Ring 实例指针链接起来。
为了更好的理解包中其他方法,我们使用一个图来表示。先构造一个 5 个元素的环,同时将每个元素的值分别设置为 1-5:
r := ring.New(5)
n := r.Len()
for i := 1; i <= n; i++ {
r.Value = i
r = r.Next()
}
其中,Len 获得当前环的元素个数,时间复杂度是 O(n)。如图:
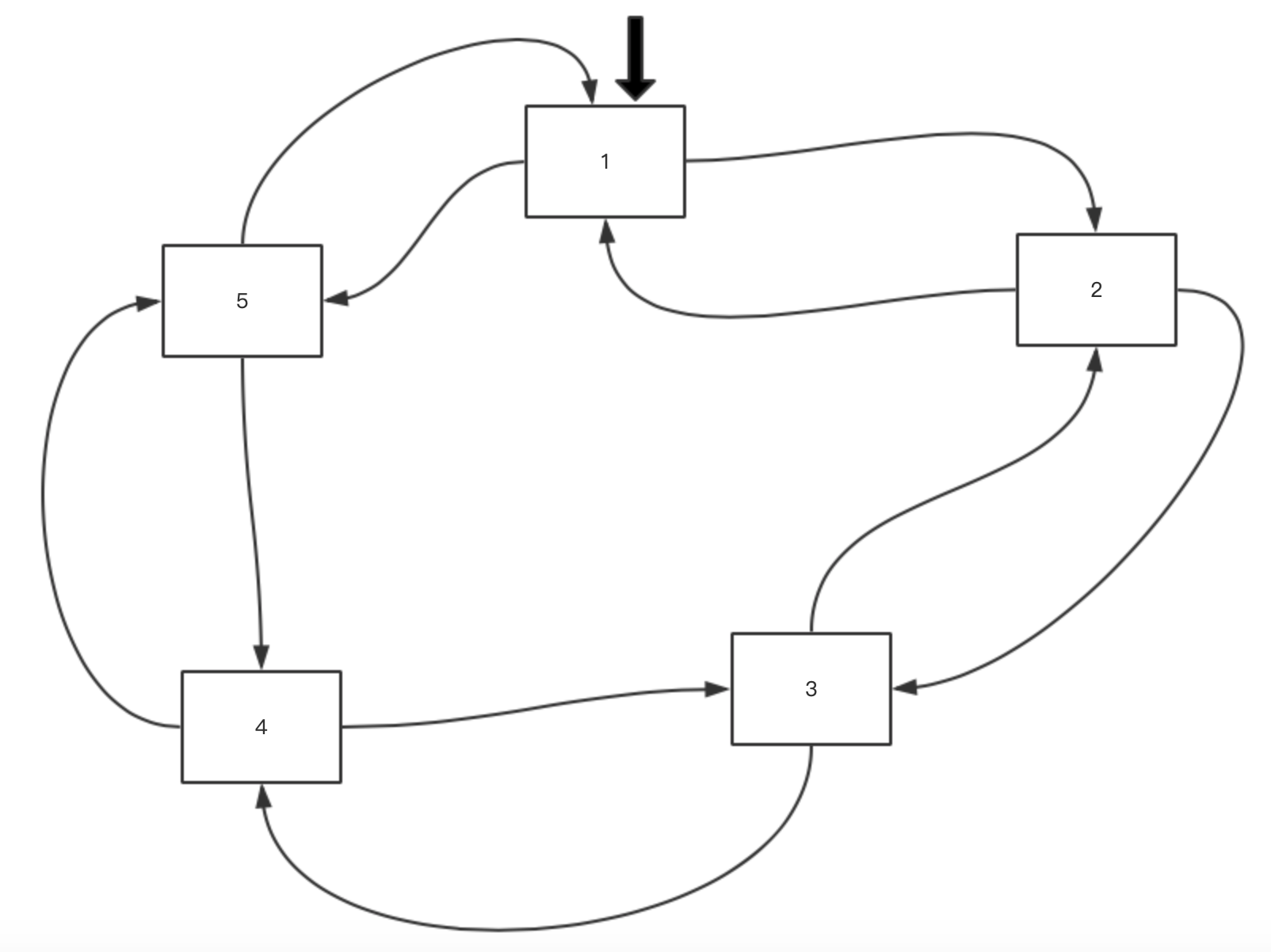
当前 r 的值是 1(图中黑色箭头所指,这是为了表示方便,虚拟的)。分别看看 Ring 结构的方法。注意,移动相关的方法,都应该用返回值赋值给原 r,比如:r = r.Next()。
1)r.Next() 和 r.Prev()
这两个方法很简单。当前 r 代表值是 1 的元素,r.Next() 返回的 r 就代表值是 2 的元素;而 r.Prev() 返回的 r 则代表值是 5 的元素。
2)r.Move()
Next 和 Prev 一次只能移动一步(注意,可以理解为移动的是上图中黑色的箭头),而 Move 可以通过指定 n 来告知移动多少步,负数表示向后移动,正数表示向前移动。实际上,内部还是依赖于 Next 或 Prev 进行移动的。
这里要特别提醒一下,因为是环,所以参数 n 应该在 n % r.Len() 这个范围,否则做的是无用功。因为环的长度需要额外 O(n) 的时间计算,因此对 n 并没有做 n % r.Len() 的处理,传递的是多少就进行多少步移动,虽然最后结果跟 n % r.Len() 是一样的。
func (r *Ring) Move(n int) *Ring {
if r.next == nil {
return r.init()
}
switch {
case n < 0:
for ; n < 0; n++ {
r = r.prev
}
case n > 0:
for ; n > 0; n-- {
r = r.next
}
}
return r
}
比如 r.Move(-2) 则把上图中的箭头移到了元素 4 处。
3)r.Do()
这是一个方便的遍历环的方法。该方法接收一个回调函数,函数的参数是当前环元素的 Value。该遍历是按照向前的方向进行的。因此,我们可以这样输出我们初始化的环:
r.Do(func(value interface{}){
fmt.Print(value.(int), " ")
})
输出:
1 2 3 4 5
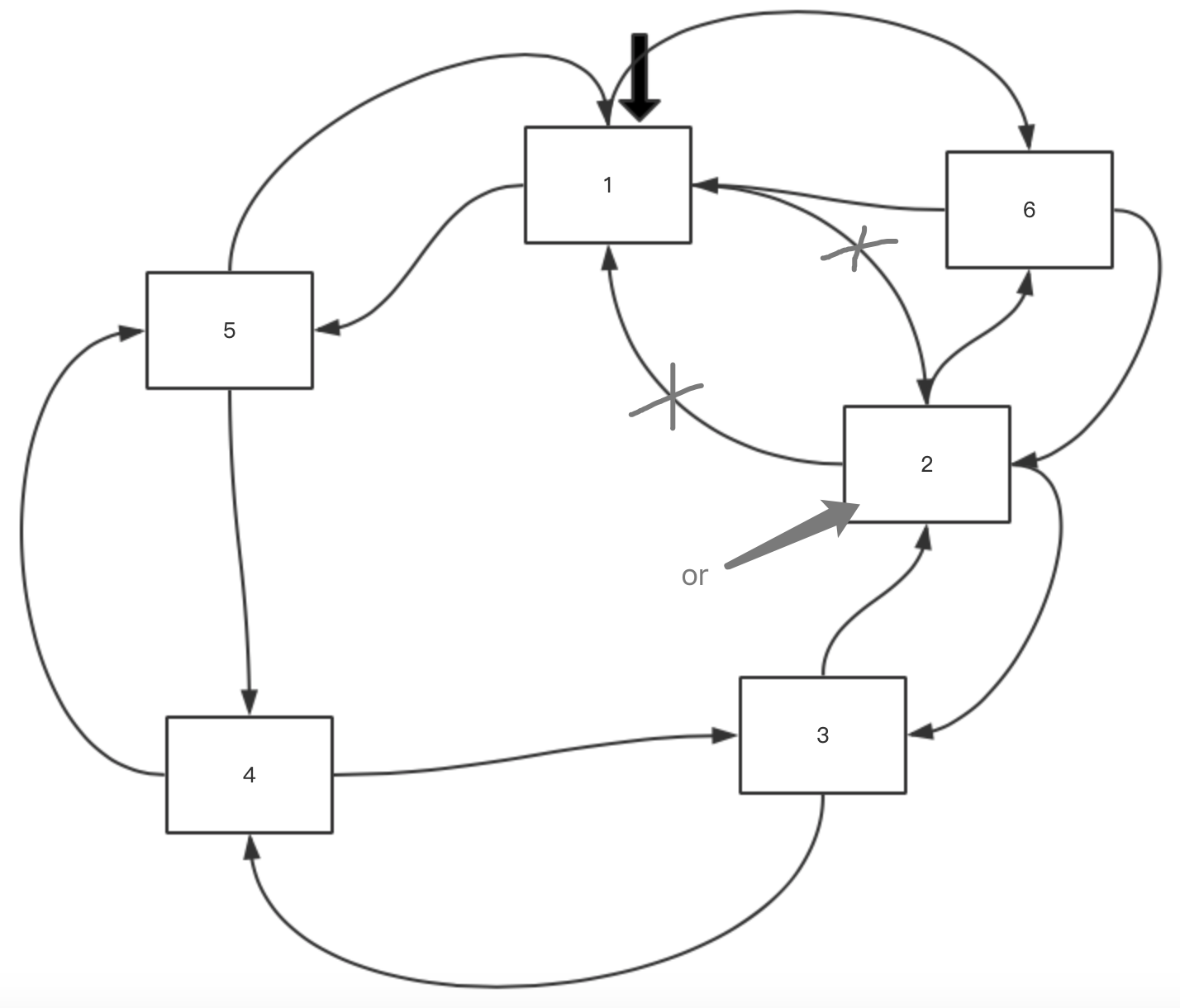
4)r.Link() 和 r.Unlink()
这两个函数的作用相反,但接收参数不同。我们先看 r.Link(),向环中增加一个元素 6:
nr := &ring.Ring{Value: 6}
or := r.Link(nr)
加上以上代码后,结果如图:
类似的,r.Unlink 则是删除元素,参数 n 表示从下个元素起删除 n%r.Len() 个元素。
dr := r.Unlink(3)
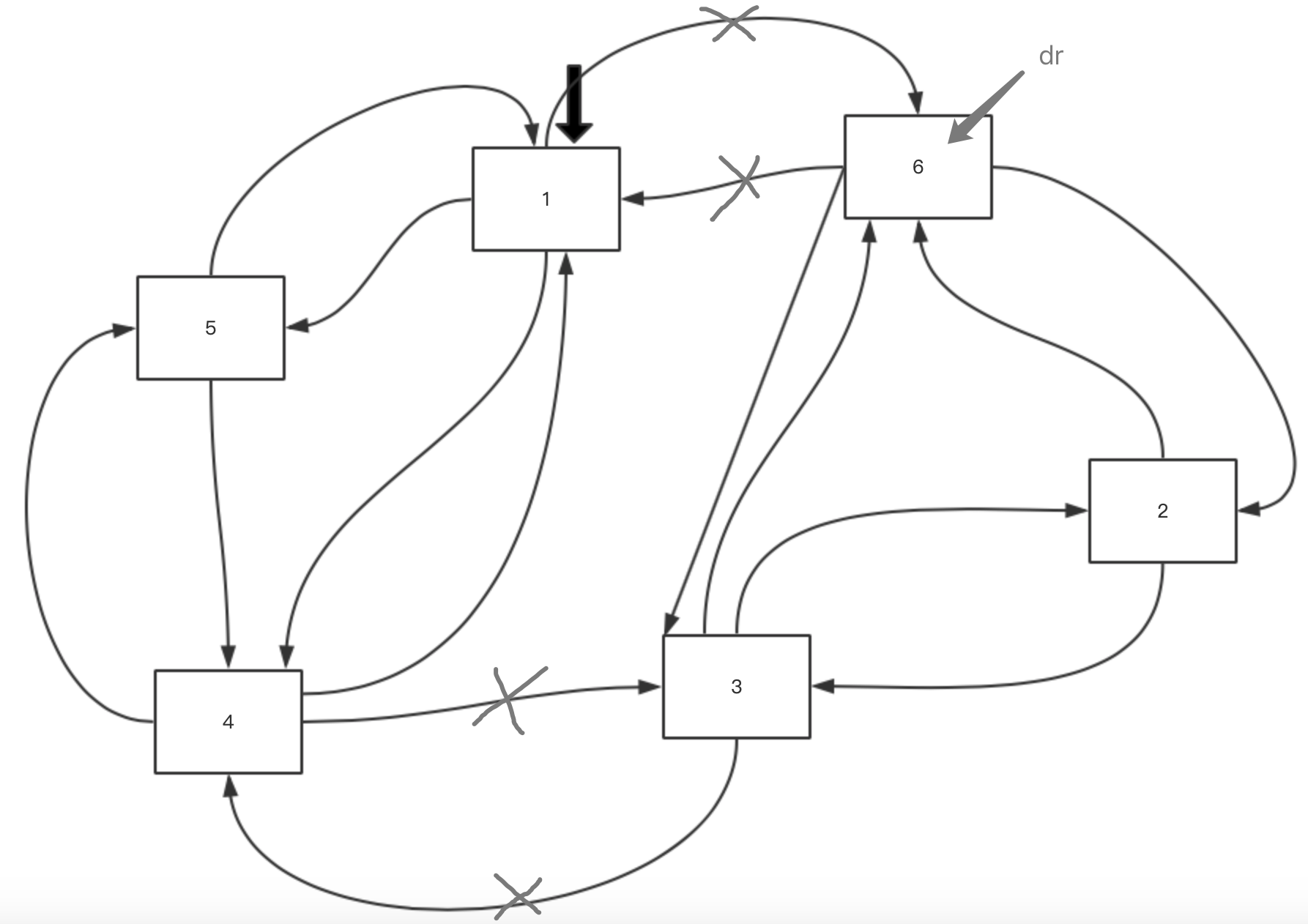
从图中可以看出,环形链表被分成了两个,原来那个即 r, 从 1 开始,依次是 4、5,而被 unlink 掉的,即 dr,从 6 开始,依次是 2、3。
讲完 container/ring,我们回到离线消息上来。
离线消息实现的两个核心方法:存和取
先看离线消息如何存。
func (o *offlineProcessor) Save(msg *Message) {
if msg.Type != MsgTypeNormal {
return
}
o.recentRing.Value = msg
o.recentRing = o.recentRing.Next()
for _, nickname := range msg.Ats {
nickname = nickname[1:]
var (
r *ring.Ring
ok bool
)
if r, ok = o.userRing[nickname]; !ok {
r = ring.New(o.n)
}
r.Value = msg
o.userRing[nickname] = r.Next()
}
}
- 根据 Ring 的使用方式,将用户消息直接存入 recentRing 中,并后移一个位置;
- 判断消息中是否有 @ 谁,需要单独为它保存一个消息列表;
这个方法在广播完消息后调用。
case msg := <-b.messageChannel:
// 给所有在线用户发送消息
for _, user := range b.users {
if user.UID == msg.User.UID {
continue
}
user.MessageChannel <- msg
}
OfflineProcessor.Save(msg)
接着看用户离线后,再次进入聊天室取消息的实现。
func (o *offlineProcessor) Send(user *User) {
o.recentRing.Do(func(value interface{}) {
if value != nil {
user.MessageChannel <- value.(*Message)
}
})
if user.isNew {
return
}
if r, ok := o.userRing[user.NickName]; ok {
r.Do(func(value interface{}) {
if value != nil {
user.MessageChannel <- value.(*Message)
}
})
delete(o.userRing, user.NickName)
}
}
首先遍历最近消息,发送给该用户。之后,如果不是新用户,查询是否有 @ 该用户的消息,有则发送给它,之后将这些消息删除。因为最近的消息是所有用户共享的,不能删除;@ 用户的消息是用户独有的,可以删除。
很显然,这个方法在用户进入聊天室后调用:
case user := <-b.enteringChannel:
// 新用户进入
b.users[user.NickName] = user
b.sendUserList()
OfflineProcessor.Send(user)
细心的读者会发现以上处理方式,用户可能会收到重复的消息。的确如此。关于消息排重我们不做讲解了,大体思路是会为消息生成 ID,消息按时间排序,去重。实际业务中,去重更多会由客户端来做。
4.7.4 小结
一个产品,非核心功能是很多的,需要不断迭代。对于聊天室,肯定还有其他更多的功能可以开发,这就留给有兴趣的读者自己去探索、实现了。
在实现功能的过程中,把需要用到的库能够系统的学习一遍,你会掌握的很牢固,比如本节中的 container/ring,希望在以后的学习工作中,你能够做到。
