5.2 缓存淘汰算法
本书讨论的缓存,是指存放在内存的。那么容量一般是有限的,因为内存是有限的。因此,当缓存容量超过一定限制时,应该移除一条或多条数据。那应该移除谁呢?答案是尽可能移除“无用”数据。那怎么判断数据是否“无用”?这就涉及到缓存淘汰算法。
常用的缓存淘汰算法有:
- FIFO(先进先出)
- LFU(最少使用)
- LRU(最近最少使用)
本节讲解具体算法实现时,我们不考虑并发(即单 goroutine 读写)和 GC 问题,所以缓存数据通过 Go 中的 map 来存储。
5.2.1 初始化项目
开始之前,我们需要为进程内缓存项目做初始化,执行下述命令(若为 Windows 系统,可根据实际情况自行调整项目的路径):
$ mkdir -p $HOME/go-programming-tour-book/cache
$ cd $HOME/go-programming-tour-book/cache
$ go mod init github.com/go-programming-tour-book/cache
5.2.2 缓存接口
我们为缓存系统提供一个接口。在我们的 cache 项目根目录创建一个 cache.go 文件,定义一个 Cache 接口,代码如下:
package cache
// Cache 缓存接口
type Cache interface {
Set(key string, value interface{})
Get(key string) interface{}
Del(key string)
DelOldest()
Len() int
}
- 设置/添加一个缓存,如果 key 存在,用新值覆盖旧值;
- 通过 key 获取一个缓存值;
- 通过 key 删除一个缓存值;
- 删除最“无用”的一个缓存值;
- 获取缓存已存在的记录数;
接下来三种算法都会实现该接口。其中 FIFO 和 LRU 的数据结构设计参考了 Go 语言的 groupcache 库。
5.2.3 FIFO(First In First Out)
FIFO,先进先出,也就是淘汰缓存中最早添加的记录。在 FIFO Cache 设计中,核心原则就是:如果一个数据最先进入缓存,那么也应该最早淘汰掉。这么认为的根据是,最早添加的记录,其不再被使用的可能性比刚添加的可能性大。
这种算法的实现非常简单,创建一个队列(一般通过双向链表实现),新增记录添加到队尾,缓存满了,淘汰队首。
5.2.2.1 FIFO 算法实现
在 cache 项目根目录创建一个 fifo 子目录,并创建一个 fifo.go 文件,存放 FIFO 算法的实现。
mdkir -p fifo
cd filo
touch filo.go
1、核心数据结构
// fifo 是一个 FIFO cache。它不是并发安全的。
type fifo struct {
// 缓存最大的容量,单位字节;
// groupcache 使用的是最大存放 entry 个数
maxBytes int
// 当一个 entry 从缓存中移除是调用该回调函数,默认为 nil
// groupcache 中的 key 是任意的可比较类型;value 是 interface{}
onEvicted func(key string, value interface{})
// 已使用的字节数,只包括值,key 不算
usedBytes int
ll *list.List
cache map[string]*list.Element
}
该结构体中,核心的两个数据结构是 *list.List 和 map[string]*list.Element,list.List 是标准库 container/list 提供的,map 的键是字符串,值是双向链表中对应节点的指针。
该结构如图所示:
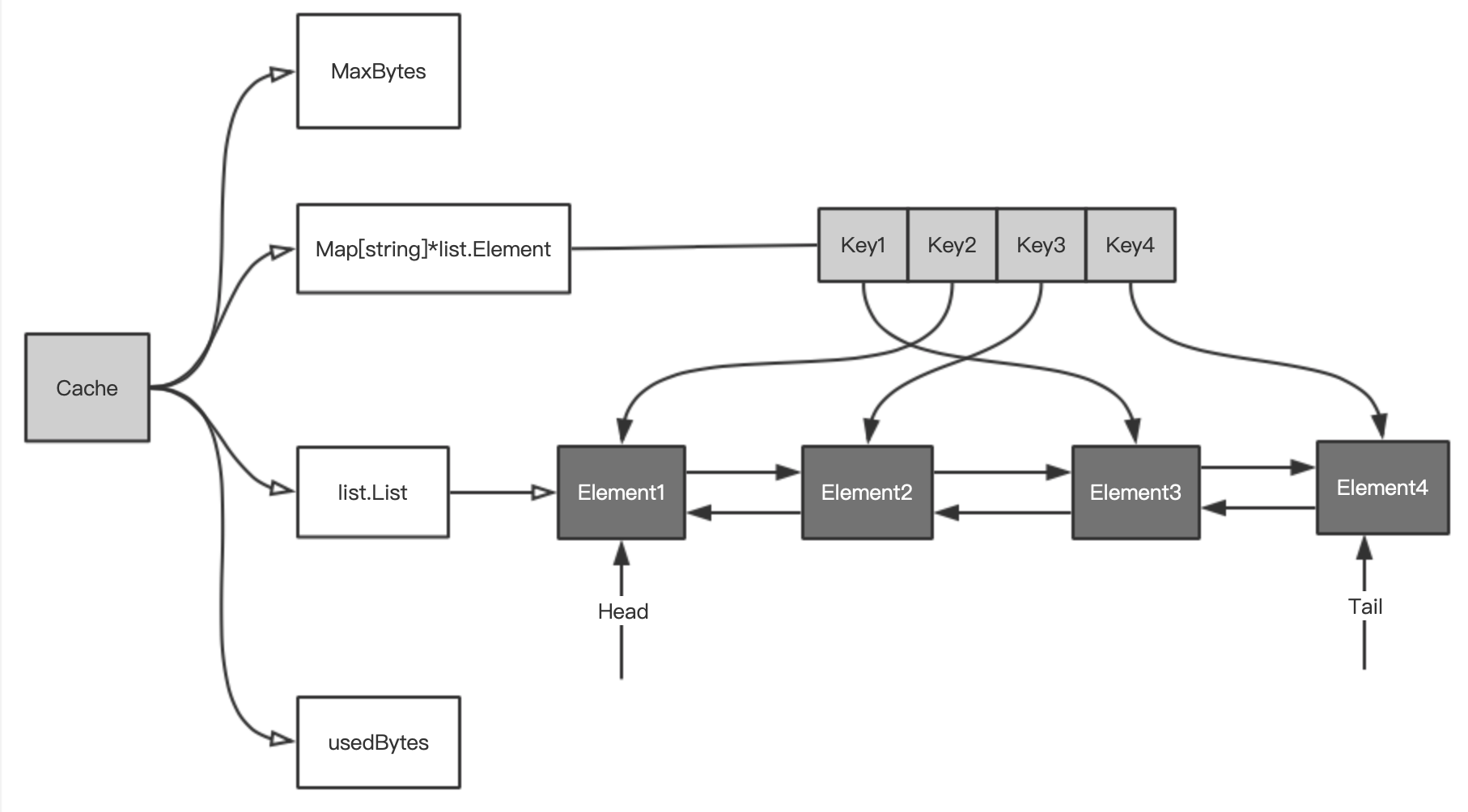
- map 用来存储键值对。这是实现缓存最简单直接的数据结构。因为它的查找和增加时间复杂度都是 O(1)。
- list.List 是 Go 标准库提供的双向链表。通过这个数据结构存放具体的值,可以做到移动记录到队尾的时间复杂度是 O(1),在在队尾增加记录时间复杂度也是 O(1),同时删除一条记录时间复杂度同样是 O(1)。
map 中存的值是 list.Element 的指针,而 Element 中有一个 Value 字段,是 interface{},也就是可以存放任意类型。当淘汰节点时,需要通过 key 从 map 中删除,因此,存入 Element 中的值是如下类型的指针:
type entry struct {
key string
value interface{}
}
func (e *entry) Len() int {
return cache.CalcLen(e.value)
}
groupcache 容量控制的是记录数,为了更精确或学习目的,我们采用了内存控制,但记录中只算 value 占用的内存,不考虑 key 的内存占用。CalcLen 函数就是计算内存用的:
func CalcLen(value interface{}) int {
var n int
switch v := value.(type) {
case cache.Value:
n = v.Len()
case string:
if runtime.GOARCH == "amd64" {
n = 16 + len(v)
} else {
n = 8 + len(v)
}
case bool, uint8, int8:
n = 1
case int16, uint16:
n = 2
case int32, uint32, float32:
n = 4
case int64, uint64, float64:
n = 8
case int, uint:
if runtime.GOARCH == "amd64" {
n = 8
} else {
n = 4
}
case complex64:
n = 8
case complex128:
n = 16
default:
panic(fmt.Sprintf("%T is not implement cache.Value", value))
}
return n
}
该函数计算各种类型的内存占用,有几点需要说明:
- int/uint 类型,根据 GOARCH 不同,占用内存不同;
- string 类型的底层由长度和字节数组构成,内存占用是 8 + len(s) 或 16 + len(s);
- 对于其他类型,要求实现 cache.Value 接口,该接口有一个 Len 方法,返回占用的内存字节数;如果没有实现该接口,则 panic;
cache.Value 接口定义如下:
package cache
type Value interface {
Len() int
}
实例化一个 FIFO 的 Cache,通过 fifo.New() 函数:
// New 创建一个新的 Cache,如果 maxBytes 是 0,表示没有容量限制
func New(maxBytes int, onEvicted func(key string, value interface{})) cache.Cache {
return &fifo{
maxBytes: maxBytes,
onEvicted: onEvicted,
ll: list.New(),
cache: make(map[string]*list.Element),
}
}
一般地,对于接口和具体类型,Go 语言推荐函数参数使用接口,返回值使用具体类型,大量的标准库遵循了这一习俗。
然而,我们这里似乎违背了这一习俗。其实这里的设计更体现了封装,内部状态更可控,对比 groupcache 的代码你会发现这一点;而且它有一个重要的特点,那就是这里的类型(fifo)只实现了 cache.Cache 接口。这种设计风格,在标准库中也存在,比如 Hash 相关的库(hash.Hash 接口),Image 相关库(image.Image 接口)。
2、新增/修改
// Set 往 Cache 尾部增加一个元素(如果已经存在,则移到尾部,并修改值)
func (f *fifo) Set(key string, value interface{}) {
if e, ok := f.cache[key]; ok {
f.ll.MoveToBack(e)
en := e.Value.(*entry)
f.usedBytes = f.usedBytes - cache.CalcLen(en.value) + cache.CalcLen(value)
en.value = value
return
}
en := &entry{key, value}
e := f.ll.PushBack(en)
f.cache[key] = e
f.usedBytes += en.Len()
if f.maxBytes > 0 && f.usedBytes > f.maxBytes {
f.DelOldest()
}
}
- 如果 key 存在,则更新对应节点的值,并将该节点移到队尾。
- 不存在则是新增场景,首先队尾添加新节点
&entry{key, value}, 并在 map 中添加 key 和节点的映射关系。 - 更新
f.usedBytes,如果超过了设定的最大值f.maxBytes,则移除“无用”的节点,对于 FIFO 则是移除队首节点。 - 如果 maxBytes = 0,表示不限内存,则不会进行移除操作。
3、查找
查找功能很简单,直接从 map 中找到对应的双向链表的节点。
// Get 从 cache 中获取 key 对应的值,nil 表示 key 不存在
func (f *fifo) Get(key string) interface{} {
if e, ok := f.cache[key]; ok {
return e.Value.(*entry).value
}
return nil
}
4、删除
根据缓存接口的定义,我们需要提供两个删除方法:根据指定的 key 删除记录和删除最“无用”的记录。
// Del 从 cache 中删除 key 对应的记录
func (f *fifo) Del(key string) {
if e, ok := f.cache[key]; ok {
f.removeElement(e)
}
}
// DelOldest 从 cache 中删除最旧的记录
func (f *fifo) DelOldest() {
f.removeElement(f.ll.Front())
}
func (f *fifo) removeElement(e *list.Element) {
if e == nil {
return
}
f.ll.Remove(e)
en := e.Value.(*entry)
f.usedBytes -= en.Len()
delete(f.cache, en.key)
if f.onEvicted != nil {
f.onEvicted(en.key, en.value)
}
}
- Del 一般用于主动删除某个缓存记录。根据 key 从 map 中获取节点,从链表中删除,并从 map 中删除;
- DelOldest 一般不主动调用,而是在内存满时自动触发(在新增方法中看到了),这就是缓存淘汰;
- 两者都会在设置了
onEvicted回调函数时,调用它;
5、获取缓存记录数
这个方法更多是为了方便测试或为数据统计提供。
// Len 返回当前 cache 中的记录数
func (f *fifo) Len() int {
return f.ll.Len()
}
5.2.3.2 测试
在 fifo 目录下创建一个测试文件:fifo_test.go,增加单元测试代码,在一个测试函数中同时测试多个功能:
func TestSetGet(t *testing.T) {
is := is.New(t)
cache := fifo.New(24, nil)
cache.DelOldest()
cache.Set("k1", 1)
v := cache.Get("k1")
is.Equal(v, 1)
cache.Del("k1")
is.Equal(0, cache.Len()) // expect to be the same
// cache.Set("k2", time.Now())
}
- 我们使用了 github.com/matryer/is 这个库。注意这行注释:
// expect to be the same,如果测试失败,这行注释会输出。如:fifo_test.go:20: 1 != 0 // expect to be the same - 最后注释的代码用来测试非基本类型,必须实现 Value 接口,方便知道内存占用,否则 panic;
接着测试自动淘汰和回调函数。
func TestOnEvicted(t *testing.T) {
is := is.New(t)
keys := make([]string, 0, 8)
onEvicted := func(key string, value interface{}) {
keys = append(keys, key)
}
cache := fifo.New(16, onEvicted)
cache.Set("k1", 1)
cache.Set("k2", 2)
cache.Get("k1")
cache.Set("k3", 3)
cache.Get("k1")
cache.Set("k4", 4)
expected := []string{"k1", "k2"}
is.Equal(expected, keys)
is.Equal(2, cache.Len())
}
5.2.2.3 小结
FIFO 实现还是比较简单,主要使用了标准库的 container/list。该算法相关方法的时间复杂度都是 O(1)。
然而该算法的问题比较明显,很多场景下,部分记录虽然是最早添加但也常被访问,但该算法会导致它们被淘汰。这样这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
5.2.4 LFU(Least Frequently Used)
LFU,即最少使用,也就是淘汰缓存中访问频率最低的记录。LFU 认为,如果数据过去被访问多次,那么将来被访问的频率也更高。LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加 1,队列重新排序,淘汰时选择访问次数最少的即可。
该算法的实现稍微复杂些。在 Go 中,我们结合标准库 container/heap 来实现。
5.2.3.1 算法实现
在 cache 项目根目录创建一个 lfu 子目录,并创建一个 lfu.go 文件,存放 LFU 算法的实现。
1、核心数据结构
// lfu 是一个 LFU cache。它不是并发安全的。
type lfu struct {
// 缓存最大的容量,单位字节;
// groupcache 使用的是最大存放 entry 个数
maxBytes int
// 当一个 entry 从缓存中移除是调用该回调函数,默认为 nil
// groupcache 中的 key 是任意的可比较类型;value 是 interface{}
onEvicted func(key string, value interface{})
// 已使用的字节数,只包括值,key 不算
usedBytes int
queue *queue
cache map[string]*entry
}
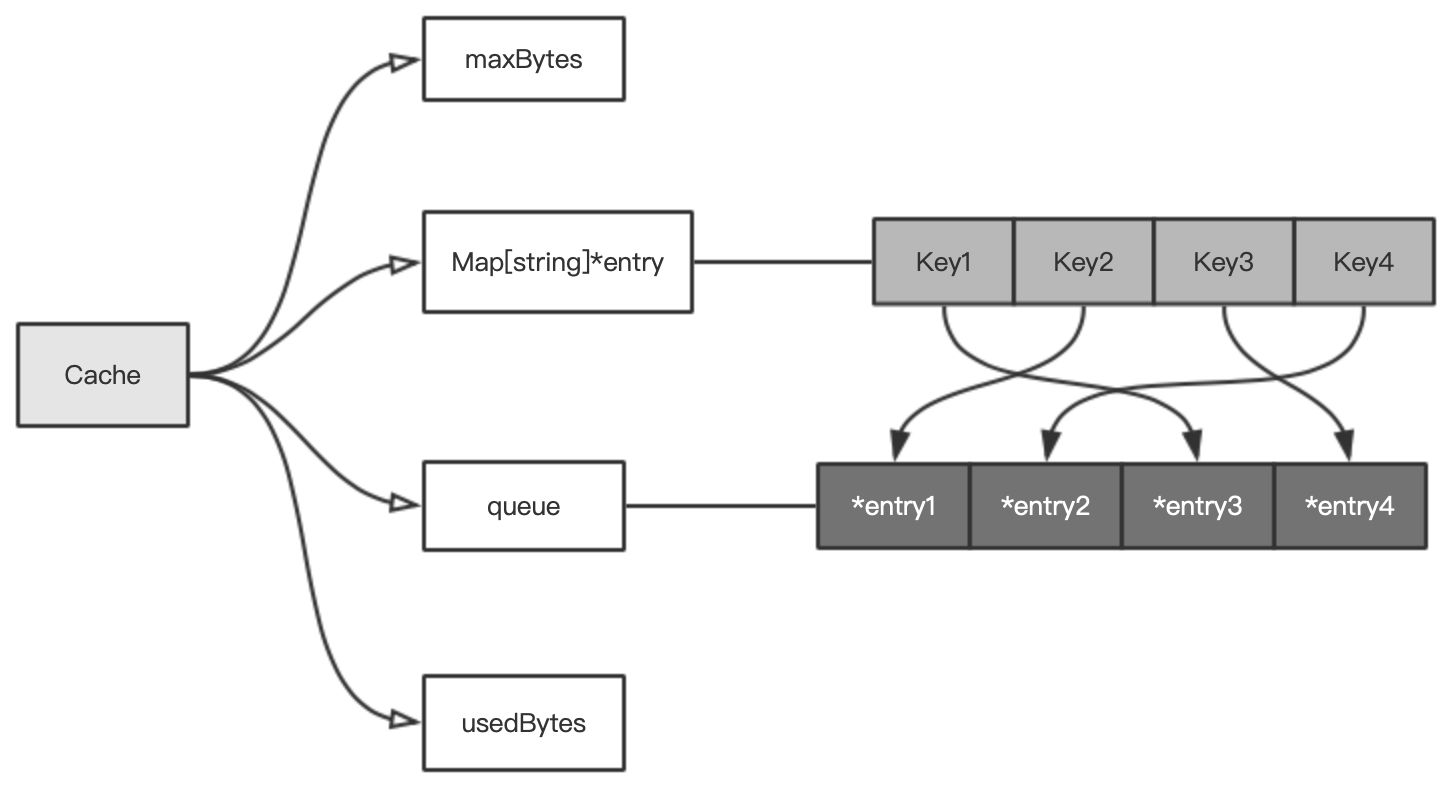
和 FIFO 算法中有两个不同点:
- 使用了 queue 而不是 container/list;
- cache 这个 map 的 value 是
*entry类型,而不是*list.Element;
这里的 queue 是什么?它定义在 lfu 目录下的 queue.go 文件中。代码如下:
type entry struct {
key string
value interface{}
weight int
index int
}
func (e *entry) Len() int {
return cache.CalcLen(e.value) + 4 + 4
}
type queue []*entry
- queue 是一个
entry指针切片; - entry 和 FIFO 中的区别是多了两个字段:weight 和 index;
- weight 表示该 entry 在 queue 中权重(优先级),访问次数越多,权重越高;
- index 代表该 entry 在堆(heap)中的索引;
LFU 算法用最小堆实现。在 Go 中,通过标准库 container/heap 实现最小堆,要求 queue 实现 heap.Interface 接口:
type Interface interface {
sort.Interface
Push(x interface{}) // add x as element Len()
Pop() interface{} // remove and return element Len() - 1.
}
看看 queue 的实现。
func (q queue) Len() int {
return len(q)
}
func (q queue) Less(i, j int) bool {
return q[i].weight < q[j].weight
}
func (q queue) Swap(i, j int) {
q[i], q[j] = q[j], q[i]
q[i].index = i
q[j].index = j
}
func (q *queue) Push(x interface{}) {
n := len(*q)
en := x.(*entry)
en.index = n
*q = append(*q, en)
}
func (q *queue) Pop() interface{} {
old := *q
n := len(old)
en := old[n-1]
old[n-1] = nil // avoid memory leak
en.index = -1 // for safety
*q = old[0 : n-1]
return en
}
前三个方法:Len、Less、Swap 是标准库 sort.Interface 接口的方法;后两个方法:Push、Pop 是 heap.Interface 要求的新方法。
至于是最大堆还是最小堆,取决于 Swap 方法的实现:< 则是最小堆,> 则是最大堆。我们这里的需求自然使用最小堆。
该数据结构如下图所示:
实例化一个 LFU 的 Cache,通过 lfu.New() 函数:
// New 创建一个新的 Cache,如果 maxBytes 是 0,表示没有容量限制
func New(maxBytes int, onEvicted func(key string, value interface{})) cache.Cache {
q := make(queue, 0, 1024)
return &lfu{
maxBytes: maxBytes,
onEvicted: onEvicted,
queue: &q,
cache: make(map[string]*entry),
}
}
因为 queue 实际上是一个 slice,避免 append 导致内存拷贝,可以提前分配一个稍大的容量。实际中,如果使用 LFU 算法,为了性能考虑,可以将最大内存限制改为最大记录数限制,这样可以更好地提前分配 queue 的容量。
2、新增/修改
// Set 往 Cache 增加一个元素(如果已经存在,更新值,并增加权重,重新构建堆)
func (l *lfu) Set(key string, value interface{}) {
if e, ok := l.cache[key]; ok {
l.usedBytes = l.usedBytes - cache.CalcLen(e.value) + cache.CalcLen(value)
l.queue.update(e, value, e.weight+1)
return
}
en := &entry{key: key, value: value}
heap.Push(l.queue, en)
l.cache[key] = en
l.usedBytes += en.Len()
if l.maxBytes > 0 && l.usedBytes > l.maxBytes {
l.removeElement(heap.Pop(l.queue))
}
}
func (q *queue) update(en *entry, value interface{}, weight int) {
en.value = value
en.weight = weight
heap.Fix(q, en.index)
}
- 如果 key 存在,则更新对应节点的值。这里调用了 queue 的 update 方法:增加权重,然后调用 heap.Fix 重建堆,重建的过程,时间复杂度是 O(log n),其中 n = quque.Len();
- key 不存在,则是新增场景,首先在堆中添加新元素
&entry{key: key, value: value}, 并在 map 中添加 key 和 entry 的映射关系。heap.Push 操作的时间复杂度是 O(log n),其中 n = quque.Len(); - 更新
l.usedBytes,如果超过了设定的最大值l.maxBytes,则移除“无用”的节点,对于 LFU 则是删除堆的 root 节点。 - 如果 maxBytes = 0,表示不限内存,那么不会进行移除操作。
3、查找
// Get 从 cache 中获取 key 对应的值,nil 表示 key 不存在
func (l *lfu) Get(key string) interface{} {
if e, ok := l.cache[key]; ok {
l.queue.update(e, e.value, e.weight+1)
return e.value
}
return nil
}
查找过程:先从 map 中查找是否存在指定的 key,存在则将权重加 1。这个过程一样会进行堆的重建,因此时间复杂度也是 O(log n)。
4、删除
// Del 从 cache 中删除 key 对应的元素
func (l *lfu) Del(key string) {
if e, ok := l.cache[key]; ok {
heap.Remove(l.queue, e.index)
l.removeElement(e)
}
}
// DelOldest 从 cache 中删除最旧的记录
func (l *lfu) DelOldest() {
if l.queue.Len() == 0 {
return
}
l.removeElement(heap.Pop(l.queue))
}
func (l *lfu) removeElement(x interface{}) {
if x == nil {
return
}
en := x.(*entry)
delete(l.cache, en.key)
l.usedBytes -= en.Len()
if l.onEvicted != nil {
l.onEvicted(en.key, en.value)
}
}
- Del 实际通过 heap.Remove 进行删除。这个过程一样需要重建堆,因此时间复杂度是 O(log n);
- DelOldest 通过 heap.Pop 得到堆顶(root)元素,这里也是权重最小的(之一),然后将其删除;
删除操作的其他过程和 FIFO 类似。
5、获取缓存记录数
可以通过 map 或 queue 获取,因为 queue 实际上是一个切片。
// Len 返回当前 cache 中的记录数
func (l *lfu) Len() int {
return l.queue.Len()
}
5.2.4.2 测试
在 lfu 目录下创建一个测试文件:lfu_test.go,增加单元测试代码。Set/Get 等的测试和 FIFO 类似:
func TestSet(t *testing.T) {
is := is.New(t)
cache := lfu.New(24, nil)
cache.DelOldest()
cache.Set("k1", 1)
v := cache.Get("k1")
is.Equal(v, 1)
cache.Del("k1")
is.Equal(0, cache.Len())
// cache.Set("k2", time.Now())
}
但在淘汰测试时,需要注意下。
func TestOnEvicted(t *testing.T) {
is := is.New(t)
keys := make([]string, 0, 8)
onEvicted := func(key string, value interface{}) {
keys = append(keys, key)
}
cache := lfu.New(32, onEvicted)
cache.Set("k1", 1)
cache.Set("k2", 2)
// cache.Get("k1")
// cache.Get("k1")
// cache.Get("k2")
cache.Set("k3", 3)
cache.Set("k4", 4)
expected := []string{"k1", "k3"}
is.Equal(expected, keys)
is.Equal(2, cache.Len())
}
我们限制内存最多只能容纳两条记录。注意注释的代码去掉和不去掉的区别。
5.2.3.3 小结
LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存是一种浪费;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
另外,因为要维护堆,算法的时间复杂度相对比较高。
5.2.5 LRU(Least Recently Used)
LRU,即最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。
LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。因此该算法的核心数据结构和 FIFO 是一样的,只是记录的移动方式不同而已。
5.2.4.1 算法实现
在 cache 项目根目录创建一个 lru 子目录,并创建一个 lru.go 文件,存放 LRU 算法的实现。
因为数据结构和 FIFO 算法一样,我们直接看核心的操作,主要关注和 FIFO 算法不同的地方。
1、新增/修改
// Set 往 Cache 尾部增加一个元素(如果已经存在,则放入尾部,并更新值)
func (l *lru) Set(key string, value interface{}) {
if e, ok := l.cache[key]; ok {
l.ll.MoveToBack(e)
en := e.Value.(*entry)
l.usedBytes = l.usedBytes - cache.CalcLen(en.value) + cache.CalcLen(value)
en.value = value
return
}
en := &entry{key, value}
e := l.ll.PushBack(en)
l.cache[key] = e
l.usedBytes += en.Len()
if l.maxBytes > 0 && l.usedBytes > l.maxBytes {
l.DelOldest()
}
}
这里和 FIFO 的实现没有任何区别。
2、查找
// Get 从 cache 中获取 key 对应的值,nil 表示 key 不存在
func (l *lru) Get(key string) interface{} {
if e, ok := l.cache[key]; ok {
l.ll.MoveToBack(e)
return e.Value.(*entry).value
}
return nil
}
和 FIFO 唯一不同的是,if 语句中多了一行代码:
l.ll.MoveToBack(e)
表示有访问就将该记录放在队列尾部。
3、删除
删除和 FIFO 完全一样,具体代码不贴了。
另外获取缓存记录数和 FIFO 也是一样的。
5.2.5.2 测试
在 lru 目录下创建一个测试文件:lru_test.go,增加单元测试代码。LRU 算法的测试和 FIFO 一样,主要看看淘汰时,是不是符合预期:
func TestOnEvicted(t *testing.T) {
is := is.New(t)
keys := make([]string, 0, 8)
onEvicted := func(key string, value interface{}) {
keys = append(keys, key)
}
cache := lru.New(16, onEvicted)
cache.Set("k1", 1)
cache.Set("k2", 2)
cache.Get("k1")
cache.Set("k3", 3)
cache.Get("k1")
cache.Set("k4", 4)
expected := []string{"k2", "k3"}
is.Equal(expected, keys)
is.Equal(2, cache.Len())
}
因为 k1 最近一直被访问,因此它不会被淘汰。
5.2.5.3 小结
LRU 是缓存淘汰算法中最常使用的算法,有一些大厂面试可能会让现场实现一个 LRU 算法,因此大家务必掌握该算法。groupcache 库使用的就是 LRU 算法。
